- Published on
Building an LLM from scratch part 5 - Pretraining on unlabeled data
- Authors

- Name
- Matt Du-Feu
- @mattdufeu
In the 5th chapter, we take the model we created in the previous chapter and train it. To do that, we need a way to figure out how "wrong" (or how far from the desired) the output is. So we're also introduced to loss functions.
Loss Function
The model outputs "logits". We need a way to measure how far from the desired output (token) these logits are. Thankfully PyTorch provides us with cross_entropy to do just that. The book goes into the details, but I won't plagiarise that here.
After each training loop (epoch), we want to take a measure of the "loss". This leads to awesome looking graphs like:
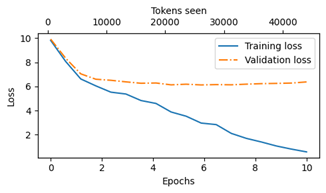
I need to do more homework on how to interpret these graphs. Thankfully this one is simple. The large gap between the training and validation loss means the model is overfitting the data. Not surprising since we're feeding it a small amount of data.
Decoding Strategies
If we took the most likely token every time, the model will generate the same text everytime. To add a bit of variety, which should result in more natural feeling text, we use torch.multinomial.
I don't understand, or think I really need to know how this works, but it effectively sometimes doesn't take the most likely token. The book provides an example, where over the course of a 1000 sampled tokens, the most likely word was chosen 582 times and only on 2 occassions it chose something different.
The decoding strategies are ways to help control the probability distribution and the selection process.
The first is "temperature", which is:
just a fancy word for dividing the logits by a number greater than 0 (pg 154)
So the higher the temperature, the more variety we get.
The second is top-k sampling. This masks out logits that are not among the top k most likely values by setting them to -infinity, which results in them having a value of 0 after applying softmax.
Using weights from OpenAI
I don't know why, but this bit got me very excited. It turns out that, because our architecture is the same as GPT-2 and OpenAI's weights can be downloaded, we can run GPT-2 ourselves.
The book takes you through downloading their weights and loading them into our LLM. Then without any other code changes, we can generate much more coherent text!
I tried the larger models but my machine (WSL Ubuntu) crashed with out-of-memory. I could only get gpt2-small working.
Summary
Brilliant chapter that brings it all together. Even though it's tiny compared to modern LLMs, going through the process of building one from the ground up and getting some reasonable output feels great.
Next, fine-tuning.